







I. Introduction▲
Le RDF est un standard (techniquement une recommandation du W3C) pour la description de ressources. Qu'est-ce qu'une ressource ? C'est une question plutÃīt profonde et la dÃĐfinition prÃĐcise est toujours l'objet de dÃĐbats. Pour nos fins, on peut imaginer que c'est tout ce que l'on peut identifier. Vous Êtes une ressource, comme l'est votre page d'accueil, ce tutoriel ou la baleine blanche de Moby Dick.
Nos exemples dans ce tutoriel seront des personnes. Ils utilisent une reprÃĐsentation RDF des vCards. RDF se reprÃĐsente le mieux sous la forme d'un diagramme de nÅuds et d'arcs. Une vCard simple pourrait ressembler à ceci en RDF :
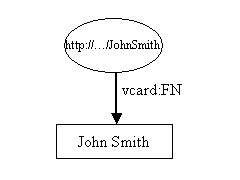
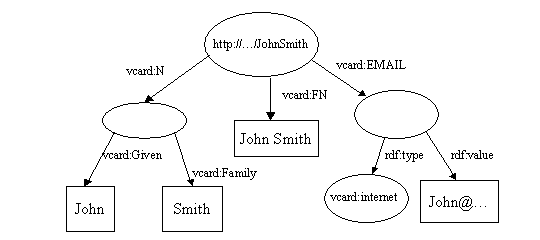
La ressource, John Smith, est reprÃĐsentÃĐe comme une ellipse et est identifiÃĐe par un identifiant de ressource uniforme (URI (1) ), dans ce cas http://.../JohnSmith. Si vous essayez d'accÃĐder à cette ressource en utilisant votre navigateur, vous n'y arriverez probablement pas ; rÃĐsistant à la tentation du poisson d'avril, vous seriez plutÃīt surpris qu'un navigateur puisse vous amener John Smith sur votre bureau. Si vous n'Êtes pas familier avec les URI, pensez-y simplement comme des noms d'apparence plutÃīt bizarre.
Les ressources possÃĻdent des propriÃĐtÃĐs. Dans ces exemples, nous sommes intÃĐressÃĐs à ce genre de propriÃĐtÃĐs qui pourraient apparaÃŪtre sur la carte de visite de John Smith. La premiÃĻre figure montre seulement une propriÃĐtÃĐ, le nom complet de John Smith. Une propriÃĐtÃĐ est reprÃĐsentÃĐe par un arc, nommÃĐ avec le nom de la propriÃĐtÃĐ. Le nom d'une propriÃĐtÃĐ est aussi une URI, mais comme les URI sont plutÃīt longues et encombrantes, le diagramme le montre dans la forme QName XML. La partie avant : s'appelle le prÃĐfixe d'espace de noms et reprÃĐsente un espace de noms. La partie aprÃĻs : s'appelle un nom local et reprÃĐsente un nom dans cet espace de noms. Les propriÃĐtÃĐs sont habituellement reprÃĐsentÃĐes dans cette forme QName quand elles sont ÃĐcrites comme du RDF/XML et c'est un raccourci pratique pour les reprÃĐsenter dans des diagrammes et dans du texte. Strictement parlant, cependant, les propriÃĐtÃĐs sont identifiÃĐes par une URI. La forme nsprefix:localname est un raccourci pour l'URI de l'espace de noms concatÃĐnÃĐ avec le nom local. Il n'y a pas besoin que l'URI d'une propriÃĐtÃĐ donne accÃĻs à quelque chose quand on y accÃĻde avec un navigateur.
Chaque propriÃĐtÃĐ a une valeur. Dans ce cas la valeur est un littÃĐral, que pour le moment nous considÃĐrerons comme une chaÃŪne (2) de caractÃĻres. Ces littÃĐraux sont montrÃĐs dans des rectangles.
Jena est une API Java qui peut Être utilisÃĐe pour crÃĐer et manipuler des graphes RDF comme celui-ci. Jena possÃĻde des classes pour reprÃĐsenter des graphes, des ressources, des propriÃĐtÃĐs et des littÃĐraux. Les interfaces reprÃĐsentant les ressources, les propriÃĐtÃĐs et les littÃĐraux sont respectivement nommÃĐes Resource, Property et Literal. Dans Jena, un graphe est appelÃĐ un modÃĻle et est reprÃĐsentÃĐ par l'interface Model.
Le code pour crÃĐer ce graphe, ou modÃĻle, est simple :
// quelques dÃĐfinitions
static String personURI = "http://somewhere/JohnSmith";
static String fullName = "John Smith";
// crÃĐer un modÃĻle vide
Model model = ModelFactory.createDefaultModel();
// crÃĐer la ressource
Resource johnSmith = model.createResource(personURI);
// ajouter la propriÃĐtÃĐ
johnSmith.addProperty(VCARD.FN, fullName);Il commence avec quelques dÃĐfinitions de constantes et ensuite crÃĐe un Model vide utilisant la mÃĐthode createDefaultModel() de ModelFactory pour crÃĐer un modÃĻle en mÃĐmoire. Jena contient d'autres implÃĐmentations de l'interface Model, par exemple celle qui utilise une base de donnÃĐes relationnelle : ces types de modÃĻles sont aussi disponibles depuis ModelFactory.
La ressource John Smith est alors crÃĐÃĐe et une propriÃĐtÃĐ y est ajoutÃĐe. La propriÃĐtÃĐ est fournie par une classe ÂŦ constante Âŧ de VCARD, qui dÃĐtient les objets reprÃĐsentant toutes les dÃĐfinitions dans le schÃĐma VCARD. Jena fournit des classes constantes pour d'autres schÃĐmas bien connus, comme RDF et RDF Schema eux-mÊmes, Dublin Core et DAML.
Le code pour crÃĐer la ressource et ajouter la propriÃĐtÃĐ peut Être ÃĐcrit d'une maniÃĻre plus compacte avec un style en cascade :
Resource johnSmith =
model.createResource(personURI)
.addProperty(VCARD.FN, fullName);Le code de travail pour cet exemple peut Être trouvÃĐ dans le rÃĐpertoire /src-examples de la distribution Jena, dans le fichier tutorial 1. Comme exercice, prenez ce code et modifiez-le pour crÃĐer une vCard simple pour vous-mÊme.
Maintenant, ajoutons un peu de dÃĐtails à cette VCARD en explorant d'autres fonctionnalitÃĐs de Jena et de RDF.
Dans le premier exemple, la valeur de la propriÃĐtÃĐ ÃĐtait un littÃĐral. Les propriÃĐtÃĐs RDF peuvent aussi prendre d'autres ressources comme valeur. En utilisant une technique RDF courante, cet exemple montre comment reprÃĐsenter les diffÃĐrentes parties du nom de John Smith :
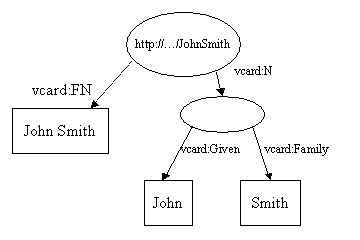
Ici, nous avons ajoutÃĐ une nouvelle propriÃĐtÃĐ, vcard:N, pour reprÃĐsenter la structure du nom de John Smith. Il y a plusieurs choses dignes d'intÃĐrÊt dans ce modÃĻle. Notez que la propriÃĐtÃĐ vcard:N prend une ressource comme valeur. Notez aussi que l'ellipse reprÃĐsentant le nom composÃĐ n'a pas d'URI. On appelle cela un nÅud anonyme.
Le code Jena pour construire cet exemple est encore une fois trÃĻs simple. D'abord quelques dÃĐclarations et puis la crÃĐation du modÃĻle vide.
// quelques dÃĐfinitions
String personURI = "http://somewhere/JohnSmith";
String givenName = "John";
String familyName = "Smith";
String fullName = givenName + " " + familyName;
// crÃĐer un modÃĻle vide
Model model = ModelFactory.createDefaultModel();
// crÃĐer la ressource
// et ajouter des propriÃĐtÃĐs en cascade
Resource johnSmith
= model.createResource(personURI)
.addProperty(VCARD.FN, fullName)
.addProperty(VCARD.N,
model.createResource()
.addProperty(VCARD.Given, givenName)
.addProperty(VCARD.Family, familyName));Le code de travail de cet exemple peut Être trouvÃĐ comme tutoriel 2 dans le rÃĐpertoire /src-examples de la distribution Jena.
II. DÃĐclarations▲
Chaque arc dans un modÃĻle RDF est appelÃĐ une dÃĐclaration. Chaque dÃĐclaration affirme un fait à propos d'une ressource. Une dÃĐclaration se compose de trois parties :
- le sujet est la ressource que quitte l'arc ;
- le prÃĐdicat est la propriÃĐtÃĐ qui donne un nom à l'arc ;
- l'objet est la ressource ou le littÃĐral pointÃĐ par l'arc.
Une telle dÃĐclaration est quelquefois appelÃĐe un triplet, Ã cause de ses trois parties.
Un modÃĻle RDF est reprÃĐsentÃĐ comme un ensemble de dÃĐclarations. Chaque appel à addProperty dans le tutoriel 2 ajoute une autre dÃĐclaration au modÃĻle. Puisqu'un modÃĻle est un ensemble de dÃĐclarations, ajouter une dÃĐclaration en double n'a pas d'effet. Les interfaces Model de Jena dÃĐfinissent une mÃĐthode listStatements(), qui retourne un StmtIterator, un sous-type de la classe Java Iterator sur toutes les dÃĐclarations dans un modÃĻle. StmtIterator possÃĻde une mÃĐthode nextStatement(), qui retourne la dÃĐclaration suivante de l'itÃĐrateur (le mÊme que next() retournerait, dÃĐjà castÃĐ en Statement). L'interface Statement fournit des mÃĐthodes d'accÃĻs au sujet, au prÃĐdicat et à l'objet de la dÃĐclaration.
Maintenant, on va utiliser cette interface pour ÃĐtendre le tutoriel 2, pour lister toutes les dÃĐclarations crÃĐÃĐes et les afficher. Le code complet pour ça se trouve dans tutoriel 3.
// liste des dÃĐclarations dans le modÃĻle
StmtIterator iter = model.listStatements();
// affiche l'objet, le prÃĐdicat et le sujet de chaque dÃĐclaration
while (iter.hasNext()) {
Statement stmt = iter.nextStatement(); // obtenir la prochaine dÃĐclaration
Resource subject = stmt.getSubject(); // obtenir le sujet
Property predicate = stmt.getPredicate(); // obtenir le prÃĐdicat
RDFNode object = stmt.getObject(); // obtenir l'objet
System.out.print(subject.toString());
System.out.print(" " + predicate.toString() + " ");
if (object instanceof Resource) {
System.out.print(object.toString());
} else {
// l'objet est un littÃĐral
System.out.print(" \"" + object.toString() + "\"");
}
System.out.println(" .");
}Puisque l'objet d'une dÃĐclaration peut Être soit une ressource soit un littÃĐral, la mÃĐthode getObject() retourne un objet de type RDFNode, qui est une superclasse commune à Resource et à Literal. L'objet sous-jacent est du type appropriÃĐ, donc le code utilise instanceof pour le dÃĐterminer et le traiter en fonction.
Quand il est lancÃĐ, ce programme devrait produire une sortie comme ceci :
http://somewhere/JohnSmith http://www.w3.org/2001/vcard-rdf/3.0#N anon:14df86:ecc3dee17b:-7fff .
anon:14df86:ecc3dee17b:-7fff http://www.w3.org/2001/vcard-rdf/3.0#Family "Smith" .
anon:14df86:ecc3dee17b:-7fff http://www.w3.org/2001/vcard-rdf/3.0#Given "John" .
http://somewhere/JohnSmith http://www.w3.org/2001/vcard-rdf/3.0#FN "John Smith" .Maintenant, vous savez pourquoi il est plus simple de dessiner des modÃĻles. Si vous regardez plus minutieusement, vous verrez que chaque ligne consiste en trois champs, reprÃĐsentant le sujet, le prÃĐdicat et l'objet de chaque dÃĐclaration. Il y a quatre arcs dans le modÃĻle, donc il y a quatre dÃĐclarations. anon:14df86:ecc3dee17b:-7fff est un identifiant interne gÃĐnÃĐrÃĐ par Jena. Ce n'est pas une URI et ne doit pas Être confondu avec une URI. Il s'agit simplement d'un label interne utilisÃĐ par l'implÃĐmentation de Jena.
Le groupe de travail RDFCore du W3C a dÃĐfini une notation simple et similaire appelÃĐe N-Triples. Le nom signifie ÂŦ triple notation Âŧ. Nous verrons dans la prochaine section que Jena a un module d'ÃĐcriture de N-triples incorporÃĐ.
III. Ãcrire du RDF▲
Jena dispose de mÃĐthodes pour lire et ÃĐcrire du RDF/XML. Elles peuvent Être utilisÃĐes pour sauvegarder un modÃĻle RDF dans un fichier et le relire plus tard.
Le tutoriel 3 a crÃĐÃĐ un modÃĻle et l'a ÃĐcrit sous forme de triplets. Le tutoriel 4 modifie le tutoriel 3 pour ÃĐcrire le modÃĻle en RDF/XML sur le flux de sortie standard. Le code est à nouveau trÃĻs simple : model.write peut prendre un argument OutputStream.
// maintenant on ÃĐcrit le modÃĻle sous forme XML dans un fichier
model.write(System.out);La sortie devrait ressembler à quelque chose comme ça :
<rdf:RDF
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:vcard='http://www.w3.org/2001/vcard-rdf/3.0#'
>
<rdf:Description rdf:about='http://somewhere/JohnSmith'>
<vcard:FN>John Smith</vcard:FN>
<vcard:N rdf:nodeID="A0"/>
</rdf:Description>
<rdf:Description rdf:nodeID="A0">
<vcard:Given>John</vcard:Given>
<vcard:Family>Smith</vcard:Family>
</rdf:Description>
</rdf:RDF>Les spÃĐcifications RDF spÃĐcifient comment reprÃĐsenter le RDF comme du XML. La syntaxe RDF/XML est assez complexe. Le lecteur est renvoyÃĐ au Primer, en cours de dÃĐveloppement par le groupe de travail RDFCore pour une introduction plus dÃĐtaillÃĐe. Cependant, regardons rapidement comment interprÃĐter ce code.
RDF est habituellement inclus dans un ÃĐlÃĐment <rdf:RDF>. L'ÃĐlÃĐment est optionnel s'il y a d'autres maniÃĻres de savoir que du XML est du RDF, mais il est gÃĐnÃĐralement prÃĐsent. L'ÃĐlÃĐment RDF dÃĐfinit les deux espaces de noms utilisÃĐs dans le document. Il y a ensuite un ÃĐlÃĐment <rdf:description> qui dÃĐcrit la ressource dont l'URI est http://somewhere/JohnSmith. Si l'attribut rdf:about ÃĐtait absent, cet ÃĐlÃĐment reprÃĐsenterait un nÅud anonyme.
L'ÃĐlÃĐment <vcard:FN> dÃĐcrit une propriÃĐtÃĐ de la ressource. Le nom de la propriÃĐtÃĐ est FN dans l'espace de noms vcard. RDF convertit ceci en une rÃĐfÃĐrence à une URI en concatÃĐnant la rÃĐfÃĐrence d'URI pour le prÃĐfixe de l'espace de noms et FN, la partie du nom local du nom. Ceci donne une rÃĐfÃĐrence d'URI de http://www.w3.org/2001/vcard-rdf/3.0#FN. La valeur de la propriÃĐtÃĐ est le littÃĐral John Smith.
L'ÃĐlÃĐment <vcard:N> est une ressource. Dans ce cas, la ressource est reprÃĐsentÃĐe par une rÃĐfÃĐrence d'URI relative. RDF convertit cela en une rÃĐfÃĐrence d'URI absolue en la concatÃĐnant avec l'URI de base du document courant.
Il y a une erreur dans ce RDF/XML ; il ne reprÃĐsente pas exactement le mÊme modÃĻle que celui que nous avons crÃĐÃĐ. Le nÅud anonyme dans le modÃĻle a ÃĐtÃĐ donnÃĐ par une rÃĐfÃĐrence d'URI. Il n'est donc plus anonyme. La syntaxe RDF/XML n'est pas capable de reprÃĐsenter tous les modÃĻles RDF ; par exemple il ne peut pas reprÃĐsenter un nÅud anonyme qui est l'objet de deux dÃĐclarations. Le module d'ÃĐcriture ÂŦ idiot Âŧ que nous utilisons pour ÃĐcrire ce RDF/XML n'essaie pas d'ÃĐcrire correctement le sous-ensemble des modÃĻles qui peuvent Être ÃĐcrits correctement. Il donne une URI à chaque nÅud anonyme, ne le rendant plus anonyme.
Jena a une interface extensible qui permet à de nouveaux modules d'ÃĐcriture pour d'autres langages de sÃĐrialisation pour RDF d'Être facilement ajoutÃĐs dessus. L'appel ci-dessus a invoquÃĐ le module d'ÃĐcriture ÂŦ idiot Âŧ standard. Jena inclut aussi un module d'ÃĐcriture RDF/XML plus sophistiquÃĐ qui peut Être invoquÃĐ en spÃĐcifiant un autre argument lors de l'appel à la mÃĐthode write() :
// On ÃĐcrit maintenant le modÃĻle en XML dans un fichier
model.write(System.out, "RDF/XML-ABBREV");Ce module d'ÃĐcriture, appelÃĐ ÂŦ PrettyWritter Âŧ, tire avantage des fonctionnalitÃĐs de la syntaxe abrÃĐgÃĐe de RDF/XML pour ÃĐcrire un modÃĻle plus compact. Il est aussi en mesure de prÃĐserver les nÅuds anonymes oÃđ cela est possible. Il n'est cependant pas appropriÃĐ pour de grands modÃĻles, la probabilitÃĐ pour que ses performances soient acceptables ÃĐtant trÃĻs faible. Pour ÃĐcrire de grands fichiers et prÃĐserver les nÅuds anonymes, les ÃĐcrire au format N-Triples :
// On ÃĐcrit maintenant le modÃĻle en N-Triples dans un fichier
model.write(System.out, "N-TRIPLE");Ceci produira une sortie similaire à celle du tutoriel 3 qui se conforme à la spÃĐcification N-Triples.
IV. Lire du RDF▲
Le tutoriel 5 dÃĐmontre comment lire les dÃĐclarations enregistrÃĐes au format RDF/XML dans un modÃĻle. Avec ce tutoriel, nous avons fourni une petite base de donnÃĐes de VCARD au format RDF/XML. Le code suivant le lira et l'ÃĐcrira dans le flux standard de sortie. Notez que pour que cette application se lance, le fichier d'entrÃĐe doit Être dans le rÃĐpertoire courant.
// crÃĐer un modÃĻle vide
Model model = ModelFactory.createDefaultModel();
// utiliser le FileManager pour trouver le fichier d'entrÃĐe
InputStream in = FileManager.get().open( inputFileName );
if (in == null) {
throw new IllegalArgumentException(
"Fichier: " + inputFileName + " non trouvÃĐ");
}
// lire le fichier RDF/XML
model.read(in, null);
// l'ÃĐcrire sur la sortie standard
model.write(System.out);Le second argument de la mÃĐthode read() appelÃĐe est l'URI qui sera utilisÃĐe pour rÃĐsoudre les URI relatives. Comme il n'y a pas de rÃĐfÃĐrences aux URI relatives dans le fichier de test, il est permis qu'il soit vide. Au lancement, ce tutoriel 5 produira une sortie XML qui ressemble à ceci :
<rdf:RDF
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:vcard='http://www.w3.org/2001/vcard-rdf/3.0#'
>
<rdf:Description rdf:nodeID="A0">
<vcard:Family>Smith</vcard:Family>
<vcard:Given>John</vcard:Given>
</rdf:Description>
<rdf:Description rdf:about='http://somewhere/JohnSmith/'>
<vcard:FN>John Smith</vcard:FN>
<vcard:N rdf:nodeID="A0"/>
</rdf:Description>
<rdf:Description rdf:about='http://somewhere/SarahJones/'>
<vcard:FN>Sarah Jones</vcard:FN>
<vcard:N rdf:nodeID="A1"/>
</rdf:Description>
<rdf:Description rdf:about='http://somewhere/MattJones/'>
<vcard:FN>Matt Jones</vcard:FN>
<vcard:N rdf:nodeID="A2"/>
</rdf:Description>
<rdf:Description rdf:nodeID="A3">
<vcard:Family>Smith</vcard:Family>
<vcard:Given>Rebecca</vcard:Given>
</rdf:Description>
<rdf:Description rdf:nodeID="A1">
<vcard:Family>Jones</vcard:Family>
<vcard:Given>Sarah</vcard:Given>
</rdf:Description>
<rdf:Description rdf:nodeID="A2">
<vcard:Family>Jones</vcard:Family>
<vcard:Given>Matthew</vcard:Given>
</rdf:Description>
<rdf:Description rdf:about='http://somewhere/RebeccaSmith/'>
<vcard:FN>Becky Smith</vcard:FN>
<vcard:N rdf:nodeID="A3"/>
</rdf:Description>
</rdf:RDF>V. PrÃĐfixes de contrÃīle▲
V-A. DÃĐfinitions de prÃĐfixes explicites▲
Dans la section prÃĐcÃĐdente, nous avons vu que la sortie XML dÃĐclarait un prÃĐfixe d'espace de noms vcard et utilisait ce prÃĐfixe pour abrÃĐger les URI. Alors que RDF utilise seulement des URI complÃĻtes, et pas cette forme raccourcie, Jena fournit des façons de contrÃīler les espaces de noms utilisÃĐs sur la sortie avec ses associations de prÃĐfixes. Voici un exemple simple :
Model m = ModelFactory.createDefaultModel();
String nsA = "http://somewhere/else#";
String nsB = "http://nowhere/else#";
Resource root = m.createResource( nsA + "root" );
Property P = m.createProperty( nsA + "P" );
Property Q = m.createProperty( nsB + "Q" );
Resource x = m.createResource( nsA + "x" );
Resource y = m.createResource( nsA + "y" );
Resource z = m.createResource( nsA + "z" );
m.add( root, P, x ).add( root, P, y ).add( y, Q, z );
System.out.println( "# -- pas de prÃĐfixes spÃĐciaux dÃĐfinis" );
m.write( System.out );
System.out.println( "# -- nsA dÃĐfini" );
m.setNsPrefix( "nsA", nsA );
m.write( System.out );
System.out.println( "# -- nsA et cat dÃĐfinis" );
m.setNsPrefix( "cat", nsB );
m.write( System.out );La sortie de ce fragment est constituÃĐe de trois morceaux de RDF/XML, avec trois associations de prÃĐfixes diffÃĐrents. D'abord celui par dÃĐfaut, sans prÃĐfixe autre que les standards :
# -- no special prefixes defined
<rdf:RDF
xmlns:j.0="http://nowhere/else#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:j.1="http://somewhere/else#" >
<rdf:Description rdf:about="http://somewhere/else#root">
<j.1:P rdf:resource="http://somewhere/else#x"/>
<j.1:P rdf:resource="http://somewhere/else#y"/>
</rdf:Description>
<rdf:Description rdf:about="http://somewhere/else#y">
<j.0:Q rdf:resource="http://somewhere/else#z"/>
</rdf:Description>
</rdf:RDF>Nous voyons que l'espace de noms rdf est dÃĐclarÃĐ automatiquement, puisqu'il est requis pour des balises comme <RDF:rdf> et <rdf:resource>. Les dÃĐclarations d'un espace de noms sont aussi requises pour l'utilisation des deux propriÃĐtÃĐs P et Q, mais puisque leurs espaces de noms n'ont pas ÃĐtÃĐ introduits dans le modÃĻle, ils obtiennent des espaces de noms inventÃĐs : j.0 et j.1.
La mÃĐthode setNsPrefix(String prefix, String URI) dÃĐclare que l'espace de noms URI peut Être abrÃĐgÃĐ par prefix. Jena requiert que prefix soit un nom d'espace de noms lÃĐgal en XML et qu'URI se termine par un caractÃĻre qui n'est pas un nom. Le module d'ÃĐcriture RDF/XML transformera ces dÃĐclarations de prÃĐfixes en dÃĐclarations d'espaces de noms XML et les utilise dans sa sortie :
# -- nsA defined
<rdf:RDF
xmlns:j.0="http://nowhere/else#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:nsA="http://somewhere/else#" >
<rdf:Description rdf:about="http://somewhere/else#root">
<nsA:P rdf:resource="http://somewhere/else#x"/>
<nsA:P rdf:resource="http://somewhere/else#y"/>
</rdf:Description>
<rdf:Description rdf:about="http://somewhere/else#y">
<j.0:Q rdf:resource="http://somewhere/else#z"/>
</rdf:Description>
</rdf:RDF>L'autre espace de noms reçoit toujours un nom construit, mais le nom nsA est maintenant utilisÃĐ dans les ÃĐtiquettes de propriÃĐtÃĐs. Il n'y a pas besoin pour le nom du prÃĐfixe d'avoir quoi que ce soit à faire avec les variables dans le code Jena :
# -- nsA and cat defined
<rdf:RDF
xmlns:cat="http://nowhere/else#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:nsA="http://somewhere/else#" >
<rdf:Description rdf:about="http://somewhere/else#root">
<nsA:P rdf:resource="http://somewhere/else#x"/>
<nsA:P rdf:resource="http://somewhere/else#y"/>
</rdf:Description>
<rdf:Description rdf:about="http://somewhere/else#y">
<cat:Q rdf:resource="http://somewhere/else#z"/>
</rdf:Description>
</rdf:RDF>Les deux prÃĐfixes sont utilisÃĐs pour la sortie, et aucun prÃĐfixe gÃĐnÃĐrÃĐ n'est requis.
V-B. DÃĐfinitions de prÃĐfixes implicites▲
Aussi bien que pour les dÃĐclarations de prÃĐfixes fournies par les appels à setNsPrefix, Jena se souviendra des prÃĐfixes qui ont ÃĐtÃĐ utilisÃĐs dans l'entrÃĐe de model.read().
Prenez la sortie produite par le fragment prÃĐcÃĐdent et collez-la dans un fichier quelconque, avec l'URL file:/tmp/fragment.rdf par exemple. Ensuite, lancez ce code :
Model m2 = ModelFactory.createDefaultModel();
m2.read( "file:/tmp/fragment.rdf" );
m2.write( System.out );Vous verrez que les prÃĐfixes de l'entrÃĐe sont prÃĐservÃĐs dans la sortie. Tous les prÃĐfixes sont ÃĐcrits, mÊme s'ils ne sont utilisÃĐs nulle part. On peut supprimer un prÃĐfixe avec removeNsPrefix(String prefix) si vous ne voulez pas le voir dans la sortie.
Puisque les N-Triples n'ont pas de courte façon d'ÃĐcrire les URI, il ne tient aucun compte des prÃĐfixes sur la sortie et n'en fournit aucun à l'entrÃĐe. La notation N3, aussi supportÃĐe par Jena, possÃĻde de tels noms de prÃĐfixes raccourcis, et les enregistre sur l'entrÃĐe et les utilise sur la sortie.
Jena a davantage d'opÃĐrations sur les associations de prÃĐfixes dÃĐtenues par un modÃĻle, comme l'extraction d'une Map Java des associations sortantes, ou l'ajout d'un groupe entier d'associations à la fois, voir la documentation de PrefixMapping pour les dÃĐtails.
VI. Paquets RDF de Jena▲
Jena est une API Java pour les applications Web sÃĐmantique. Le paquet-clÃĐ RDF pour le dÃĐveloppeur d'applications est com.hp.hpl.jena.rdf.model. L'API a ÃĐtÃĐ dÃĐfinie en termes d'interfaces donc le code de l'application peut fonctionner avec diffÃĐrentes implÃĐmentations sans changement. Ce paquet contient des interfaces pour reprÃĐsenter des modÃĻles, des ressources, des propriÃĐtÃĐs, des littÃĐraux, des dÃĐclarations et tous les autres concepts-clÃĐs de RDF, et une ModelFactory pour crÃĐer des modÃĻles. Ainsi ce code d'application reste indÃĐpendant de l'implÃĐmentation, il est prÃĐfÃĐrable qu'il utilise des interfaces dans la mesure du possible et pas les implÃĐmentations de classes spÃĐcifiques.
Le paquet com.hp.hpl.jena.tutorial contient le code source du travail pour tous les exemples utilisÃĐs dans ce tutoriel.
Les paquets com.hp.hpl...jenaimpl contiennent l'implÃĐmentation des classes qui peuvent Être communes à plusieurs implÃĐmentations. Par exemple, elles dÃĐfinissent les classes ResourceImpl, PropertyImpl et LiteralImpl, qui peuvent Être utilisÃĐes directement ou dÃĐrivÃĐes par diffÃĐrentes implÃĐmentations. Les applications doivent rarement, voire jamais, utiliser ces classes directement. Par exemple, plutÃīt que de crÃĐer une nouvelle instance de ResourceImpl, il vaut mieux utiliser la mÃĐthode createResource quel que soit le modÃĻle utilisÃĐ. Ainsi, si l'implÃĐmentation du modÃĻle a utilisÃĐ une implÃĐmentation optimisÃĐe de Resource, alors aucune conversion entre les deux types ne sera nÃĐcessaire.
VII. Naviguer dans un modÃĻle▲
Jusqu'ici, ce tutoriel a traitÃĐ principalement de la crÃĐation, de la lecture et de l'ÃĐcriture de modÃĻles RDF. Il est maintenant temps de traiter de l'accÃĻs à l'information tenue dans un modÃĻle.
Compte tenu de l'URI d'une ressource, l'objet de ressource peut Être rÃĐcupÃĐrÃĐ depuis un modÃĻle en utilisant la mÃĐthode Model.getResource(String uri). Cette mÃĐthode est dÃĐfinie pour retourner un objet Resource s'il en existe un dans le modÃĻle, ou autrement d'en crÃĐer un nouveau. Par exemple, pour rÃĐcupÃĐrer la ressource John Smith du modÃĻle lu du fichier dans le tutoriel 5 :
// On rÃĐcupÃĻre la ressource vcard de John Smith du modÃĻle
Resource vcard = model.getResource(johnSmithURI);L'interface Resource dÃĐfinit un nombre de mÃĐthodes pour accÃĐder aux propriÃĐtÃĐs d'une ressource. La mÃĐthode Resource.getProperty(Property p) accÃĻde à la propriÃĐtÃĐ de la ressource. Cette mÃĐthode ne suit pas l'habituelle convention des accesseurs de Java en ce que le type de l'objet retournÃĐ est Statement, pas la Property que vous attendiez. Retourner l'ensemble de la dÃĐclaration permet à l'application d'accÃĐder à la valeur de la propriÃĐtÃĐ utilisant une de ses mÃĐthodes accesseurs qui retourne l'objet de la dÃĐclaration. Par exemple pour rÃĐcupÃĐrer la ressource qui est la valeur de la propriÃĐtÃĐ vcard:N :
// rÃĐcupÃĐrer la valeur de la propriÃĐtÃĐ N
Resource name = (Resource) vcard.getProperty(VCARD.N)
.getObject();En gÃĐnÃĐral, l'objet de la dÃĐclaration pourrait Être une ressource ou un littÃĐral, ainsi le code de l'application, sachant que la valeur doit Être une ressource, caste l'objet retournÃĐ. L'une des choses que Jena essaie de faire est de fournir des mÃĐthodes de types spÃĐcifiques ainsi l'application n'a pas à caster et la vÃĐrification du type peut Être faite au moment de la compilation. Le fragment de code ci-dessus peut Être plus commodÃĐment ÃĐcrit :
// On rÃĐcupÃĻre la valeur de la propriÃĐtÃĐ FN
Resource name = vcard.getProperty(VCARD.N)
.getResource();De mÊme, la valeur littÃĐrale d'une propriÃĐtÃĐ peut Être rÃĐcupÃĐrÃĐe :
// rÃĐcupÃĻre le nom de la propriÃĐtÃĐ donnÃĐe
String fullName = vcard.getProperty(VCARD.FN)
.getString();Dans cet exemple, la ressource VCARD a seulement une propriÃĐtÃĐ vcard:FN et une propriÃĐtÃĐ vcard:N. RDF autorise une ressource à rÃĐpÃĐter une propriÃĐtÃĐ ; par exemple John peut avoir plus d'un surnom. Donnons-lui en deux :
// ajoute deux propriÃĐtÃĐs surnoms à la vcard
vcard.addProperty(VCARD.NICKNAME, "Smithy")
.addProperty(VCARD.NICKNAME, "Adman");Comme prÃĐcÃĐdemment notÃĐ, Jena reprÃĐsente un modÃĻle RDF comme un ensemble de dÃĐclarations, ainsi ajouter une dÃĐclaration avec le sujet, le prÃĐdicat et l'objet comme celui dÃĐjà dans le modÃĻle n'aura aucun effet. Jena ne dÃĐfinit pas lequel des deux surnoms prÃĐsents dans le modÃĻle sera retournÃĐ. Le rÃĐsultat de l'appel à vcard.getProperty(VCARD.NICKNAME) est indÃĐterminÃĐ. Jena retournera une des valeurs, mais il n'y a aucune garantie que deux appels consÃĐcutifs retournent la mÊme valeur.
S'il est possible qu'une propriÃĐtÃĐ apparaisse plus d'une fois, alors la mÃĐthode Resource.listProperties(Property p) peut Être utilisÃĐe pour retourner un itÃĐrateur qui les listera tous. Cette mÃĐthode renvoie un itÃĐrateur qui retourne des objets de type Statement. On peut lister les surnoms comme ceci :
// mettre en place la sortie
System.out.println("Les surnoms de \""
+ fullName + "\" sont :");
// liste les surnoms
StmtIterator iter = vcard.listProperties(VCARD.NICKNAME);
while (iter.hasNext()) {
System.out.println(" " + iter.nextStatement()
.getObject()
.toString());
}Ce code peut Être trouvÃĐ dans le tutoriel 6. L'itÃĐrateur de dÃĐclarations iter produit toutes les dÃĐclarations avec un sujet vcard et un prÃĐdicat VCARD.NICKNAME, ainsi boucler sur lui nous permet d'aller chercher chaque dÃĐclaration en utilisant nextStatement(), rÃĐcupÃĐrant le champ objet, et en le convertissant en chaÃŪne de caractÃĻres. Le code produit la sortie suivante lorsqu'il est exÃĐcutÃĐ :
Les surnoms de "John Smith" sont :
Smithy
AdmanToutes les propriÃĐtÃĐs d'une ressource peuvent Être listÃĐes en utilisant la mÃĐthode listProperties() sans un argument.
VIII. RequÊter un modÃĻle▲
La section prÃĐcÃĐdente traitait du cas de la navigation d'un modÃĻle à partir d'une ressource avec une URI connue. Cette section traite de la recherche d'un modÃĻle. Le noyau de l'API Jena supporte seulement une requÊte limitÃĐe primitive. Les ÃĐquipements les plus puissants de la requÊte RDQL sont dÃĐcrits ailleurs.
La mÃĐthode Model.listStatements(), qui liste toutes les dÃĐclarations dans un modÃĻle, est peut-Être la plus cruelle façon de requÊter un modÃĻle. Son utilisation n'est pas recommandÃĐe sur les trÃĻs grands modÃĻles. Model.listSubjects() est similaire, mais renvoie un itÃĐrateur sur toutes les ressources qui ont des propriÃĐtÃĐs, c'est-à -dire qui sont l'objet de quelques dÃĐclarations.
Model.listSubjectsWithProperty(Property p, RDFNode o) retournera un itÃĐrateur sur toutes les ressources qui ont la propriÃĐtÃĐ p avec la valeur o. Si nous supposons que seules les ressources de VCARD ont la propriÃĐtÃĐ vcard:FN, et que dans nos donnÃĐes, toutes ces ressources ont une telle propriÃĐtÃĐ, alors nous pouvons trouver toutes les vcard comme ceci :
// liste les vcard
ResIterator iter = model.listSubjectsWithProperty(VCARD.FN);
while (iter.hasNext()) {
Resource r = iter.nextResource();
...
}Toutes ces mÃĐthodes de requÊte sont simplement du sucre syntaxique sur une mÃĐthode de requÊte primitive model.listStatements(Selector s). Cette mÃĐthode renvoie un itÃĐrateur sur toutes les dÃĐclarations dans le modÃĻle ÂŦ sÃĐlectionnÃĐ Âŧ par s. L'interface de sÃĐlection est conçue pour Être extensible, mais pour l'instant, il y a seulement une implÃĐmentation de celle-ci, la classe SimpleSelector du paquet com.hp.hpl.jena.rdf.model. L'utilisation de SimpleSelector est une des rares occasions dans Jena oÃđ il est nÃĐcessaire d'utiliser une classe spÃĐcifique plutÃīt qu'une interface. Le constructeur de SimpleSelector prend trois arguments :
Selector selector = new SimpleSelector(subject, predicate, object)Ce sÃĐlecteur sÃĐlectionnera toutes les dÃĐclarations ayant un sujet qui correspond à subject, un prÃĐdicat qui correspond à predicate et un objet qui correspond à object. Si la valeur null est fournie dans toutes les positions, il correspond à tout ; autrement il correspond à des ressources ÃĐgales correspondantes ou bien à des littÃĐraux. Deux ressources sont ÃĐgales si elles ont la mÊme URI ou le mÊme nÅud anonyme ; deux littÃĐraux sont les mÊmes si tous leurs composants sont ÃĐgaux. Ainsi :
Selector selector = new SimpleSelector(null, null, null);sÃĐlectionnera toutes les dÃĐclarations dans un modÃĻle.
Selector selector = new SimpleSelector(null, VCARD.FN, null);sÃĐlectionnera toutes les dÃĐclarations ayant VCARD.FN comme prÃĐdicat, peu importe le sujet et l'objet. Comme un raccourci spÃĐcial,
listStatements( S, P, O )est ÃĐquivalent Ã
listStatements( new SimpleSelector( S, P, O ) )Le code suivant, qui peut Être trouvÃĐ dans son intÃĐgralitÃĐ dans le tutoriel 7 liste les noms complets sur toutes les vcard dans la base de donnÃĐes.
// sÃĐlectionne toutes les ressources avec une propriÃĐtÃĐ VCARD.FN
ResIterator iter = model.listSubjectsWithProperty(VCARD.FN);
if (iter.hasNext()) {
System.out.println("La base de donnÃĐes contient les vcard de :");
while (iter.hasNext()) {
System.out.println(" " + iter.nextStatement()
.getProperty(VCARD.FN)
.getString());
}
} else {
System.out.println("Aucune vcard n'a ÃĐtÃĐ trouvÃĐe dans la base de donnÃĐes");
}Cela doit produire une sortie similaire à ce qui suit :
La base de donnÃĐes contient les vcard de :
Sarah Jones
John Smith
Matt Jones
Becky SmithVotre prochain exercice est de modifier ce code pour utiliser SimpleSelector à la place de listSubjectsWithProperty.
Voyons comment implÃĐmenter un certain contrÃīle plus fin sur les dÃĐclarations sÃĐlectionnÃĐes. SimpleSelector peut Être dÃĐrivÃĐ et sa mÃĐthode de sÃĐlection modifiÃĐe pour effectuer un filtrage supplÃĐmentaire :
// sÃĐlectionne toutes les ressources avec une propriÃĐtÃĐ VCARD.FN
// dont la valeur se termine avec "Smith"
StmtIterator iter = model.listStatements(
new SimpleSelector(null, VCARD.FN, (RDFNode) null) {
public boolean selects(Statement s)
{return s.getString().endsWith("Smith");}
});Cet ÃĐchantillon de code utilise une technique propre à Java qui consiste à surcharger la dÃĐfinition d'une mÃĐthode inline lors de la crÃĐation d'une instance de la classe. Ici, la mÃĐthode selects(...) vÃĐrifie que le nom complet se termine par ÂŦ Smith Âŧ. Il est important de noter que le filtrage basÃĐ sur les arguments sujet, prÃĐdicat et objet prend place avant que la mÃĐthode selects(...) soit appelÃĐe, de sorte que le test supplÃĐmentaire ne sera appliquÃĐ qu'aux dÃĐclarations correspondantes.
Le code complet peut Être trouvÃĐ dans le tutoriel 8 et produit une sortie comme ceci :
La base de donnÃĐes contient des vcard pour :
John Smith
Becky SmithVous pourriez penser que :
/ fait tout le filtrage dans la mÃĐthode selects
StmtIterator iter = model.listStatements(
new
SimpleSelector(null, null, (RDFNode) null) {
public boolean selects(Statement s) {
return (subject == null || s.getSubject().equals(subject))
&& (predicate == null || s.getPredicate().equals(predicate))
&& (object == null || s.getObject().equals(object))
}
}
});est ÃĐquivalent à  :
StmtIterator iter =
model.listStatements(new SimpleSelector(subject, predicate, object)Alors que fonctionnellement elles peuvent Être ÃĐquivalentes, la premiÃĻre forme listera tous les ÃĐtats dans le modÃĻle et testera chacun d'eux individuellement, tandis que la seconde permettra de maintenir les index par l'implÃĐmentation pour amÃĐliorer les performances. Essayez-le sur un grand modÃĻle et voyez par vous-mÊme, mais faites une tasse de cafÃĐ d'abord.
IX. OpÃĐrations sur les modÃĻles▲
Jena fournit trois opÃĐrations pour manipuler des modÃĻles dans leur ensemble. Ce sont des opÃĐrations ensemblistes communes d'union, d'intersection et de diffÃĐrence.
L'union de deux modÃĻles est l'union des ensembles de dÃĐclarations qui reprÃĐsentent chaque modÃĻle. C'est l'une des opÃĐrations clÃĐs que la conception de RDF supporte. Il permet à des donnÃĐes provenant de sources de donnÃĐes diffÃĐrentes d'Être fusionnÃĐes. ConsidÃĐrons les deux modÃĻles suivants :
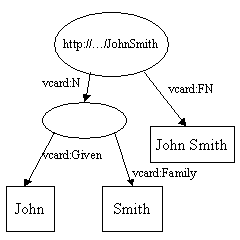
et :
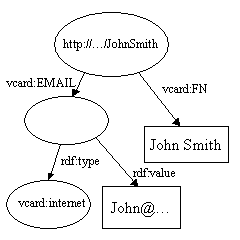
Quand ils sont fusionnÃĐs, les deux nÅuds http://.../JohnSmith sont fusionnÃĐs en un seul et l'arc vcard:FN dupliquÃĐ est supprimÃĐ pour produire :
Regardons le code pour faire ça (le code complet est dans le tutoriel 9) et voyons ce qu'il se passe.
// lit les fichiers RDF/XML
model1.read(new InputStreamReader(in1), "");
model2.read(new InputStreamReader(in2), "");
// fusionne les modÃĻles
Model model = model1.union(model2);
// affiche le modÃĻle comme RDF/XML
model.write(system.out, "RDF/XML-ABBREV");La sortie produite par le module d'ÃĐcriture ÃĐlÃĐgant ressemble à ceci :
<rdf:RDF
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
xmlns:vcard="http://www.w3.org/2001/vcard-rdf/3.0#">
<rdf:Description rdf:about="http://somewhere/JohnSmith/">
<vcard:EMAIL>
<vcard:internet>
<rdf:value>John@somewhere.com</rdf:value>
</vcard:internet>
</vcard:EMAIL>
<vcard:N rdf:parseType="Resource">
<vcard:Given>John</vcard:Given>
<vcard:Family>Smith</vcard:Family>
</vcard:N>
<vcard:FN>John Smith</vcard:FN>
</rdf:Description>
</rdf:RDF>MÊme si vous n'Êtes pas familier avec les dÃĐtails de la syntaxe RDF/XML, il devrait Être raisonnablement clair que les modÃĻles ont fusionnÃĐ comme prÃĐvu. L'intersection et la diffÃĐrence des modÃĻles peuvent Être calculÃĐes de maniÃĻre similaire, utilisant les mÃĐthodes .intersection(Model) et .difference(Model) ; voir la Javadoc de la diffÃĐrence et de l'intersection pour plus de dÃĐtails.
X. Les conteneurs▲
RDF dÃĐfinit un type particulier de ressources pour reprÃĐsenter des collections de choses. Ces ressources sont appelÃĐes des conteneurs. Les membres d'un conteneur peuvent Être soit des littÃĐraux, soit des ressources. Il y a trois types de conteneurs :
- un BAG est une collection non ordonnÃĐe ;
- une ALT est une collection non ordonnÃĐe destinÃĐe à reprÃĐsenter des alternatives ;
- une SEQ est une collection ordonnÃĐe.
Un conteneur est reprÃĐsentÃĐ par une ressource. Cette ressource aura une propriÃĐtÃĐ rdf:type dont la valeur devrait Être l'un des rdf:Bag, rdf:Alt ou rdf:Seq, ou une sous-classe de l'un d'eux, selon le type du conteneur. Le premier membre du conteneur est la valeur de la propriÃĐtÃĐ rdf:_1 du conteneur ; le second est la valeur de la propriÃĐtÃĐ rdf:_2 du conteneur et ainsi de suite. Les propriÃĐtÃĐs rdf:_nnn sont connues comme des propriÃĐtÃĐs ordinales.
Par exemple, le modÃĻle d'un simple sac contenant les vcard des Smith pourrait ressembler à ceci :
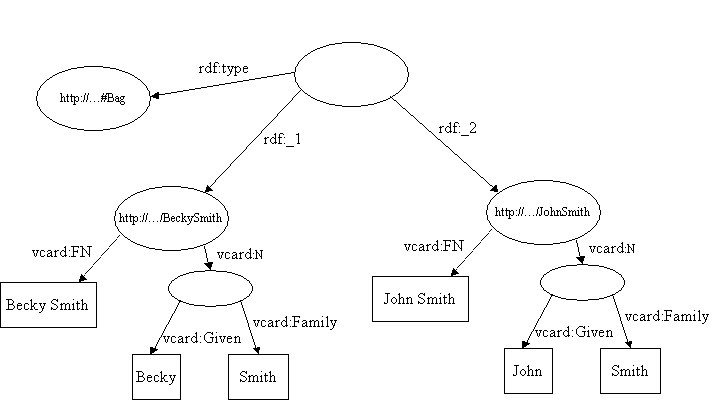
Alors que les membres du sac sont reprÃĐsentÃĐs par les propriÃĐtÃĐs rdf:_1, rdf:_2, etc., l'ordre des propriÃĐtÃĐs n'est pas significatif. On pourrait ÃĐchanger les valeurs de l'attribut des propriÃĐtÃĐs rdf:_1 et rdf:_2 et le modÃĻle rÃĐsultant reprÃĐsenterait la mÊme information.
Les Alt sont destinÃĐes à reprÃĐsenter des alternatives. Par exemple, prenons une ressource qui reprÃĐsente un produit logiciel. Il pourrait avoir une propriÃĐtÃĐ pour indiquer d'oÃđ il pourrait Être obtenu. La valeur de cette propriÃĐtÃĐ pourrait Être une collection Alt contenant diffÃĐrents sites à partir desquels elle peut Être tÃĐlÃĐchargÃĐe. Les Alt ne sont pas ordonnÃĐes, cependant la propriÃĐtÃĐ rdf:_1 a une signification particuliÃĻre : elle reprÃĐsente le choix par dÃĐfaut.
Alors que les conteneurs peuvent Être manipulÃĐs en utilisant les mÃĐcanismes de base des ressources et des propriÃĐtÃĐs, Jena possÃĻde d'explicites interfaces et implÃĐmentations de classes pour les manipuler. Ce n'est pas une bonne idÃĐe d'avoir un objet manipulant un conteneur, et à la mÊme pÃĐriode de modifier l'ÃĐtat de ce conteneur en utilisant les mÃĐthodes de plus bas niveau.
Essayons de modifier le tutoriel 8 pour crÃĐer ce sac :
// crÃĐer un sac
Bag smiths = model.createBag();
// sÃĐlectionner toutes les ressources avec une propriÃĐtÃĐ VCARD.FN
// dont la valeur se termine avec "Smith"
StmtIterator iter = model.listStatements(
new SimpleSelector(null, VCARD.FN, (RDFNode) null) {
public boolean selects(Statement s) {
return s.getString().endsWith("Smith");
}
});
// ajouter les Smith au sac
while (iter.hasNext()) {
smiths.add(iter.nextStatement().getSubject());
}Si nous ÃĐcrivons ce modÃĻle, il contient quelque chose comme ce qui suit :
<rdf:RDF
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:vcard='http://www.w3.org/2001/vcard-rdf/3.0#'
>
...
<rdf:Description rdf:nodeID="A3">
<rdf:type rdf:resource='http://www.w3.org/1999/02/22-rdf-syntax-ns#Bag'/>
<rdf:_1 rdf:resource='http://somewhere/JohnSmith/'/>
<rdf:_2 rdf:resource='http://somewhere/RebeccaSmith/'/>
</rdf:Description>
</rdf:RDF>qui reprÃĐsente la ressource sac.
L'interface du conteneur fournit un itÃĐrateur pour lister le contenu d'un conteneur :
// affiche les membres du sac
NodeIterator iter2 = smiths.iterator();
if (iter2.hasNext()) {
System.out.println("Le sac contient :");
while (iter2.hasNext()) {
System.out.println(" " +
((Resource) iter2.next())
.getProperty(VCARD.FN)
.getString());
}
} else {
System.out.println("Le sac est vide");
}qui produit la sortie suivante :
Le sac contient :
John Smith
Becky SmithUn exemple de code exÃĐcutable peut Être trouvÃĐ dans le tutoriel 10, qui recolle les morceaux ci-dessus dans un exemple complet.
Les classes de Jena offrent des mÃĐthodes pour manipuler les conteneurs incluant l'ajout de nouveaux membres, l'insertion de nouveaux membres au milieu d'un conteneur et supprimer des membres existants. Les classes conteneurs de Jena garantissent actuellement que la liste des propriÃĐtÃĐs ordinales utilisÃĐes commence à rdf:_01 et soit contiguÃŦ. Le groupe de travail RDFCore a assoupli cette contrainte, ce qui permet une reprÃĐsentation partielle des conteneurs. Il s'agit donc d'une zone de Jena qui peut Être changÃĐe dans le futur.
XI. Plus à propos des littÃĐraux et des types de donnÃĐes▲
Les littÃĐraux RDF ne sont pas de simples chaÃŪnes de caractÃĻres. Les littÃĐraux peuvent avoir une ÃĐtiquette de langue pour indiquer la langue du littÃĐral. Le littÃĐral ÂŦ chat Âŧ avec une ÃĐtiquette de langue anglaise est considÃĐrÃĐ comme diffÃĐrent du littÃĐral ÂŦ chat Âŧ avec une ÃĐtiquette de langue française. Ce comportement plutÃīt ÃĐtrange est un artefact de la syntaxe RDF/XML originale.
En outre, il y a vraiment deux sortes de littÃĐraux. Dans l'une, la composante chaÃŪne de caractÃĻres est juste ça, une chaÃŪne de caractÃĻres ordinaire. Dans l'autre composante chaÃŪne de caractÃĻres, cela devrait Être un fragment bien ÃĐquilibrÃĐ de XML. Quand un modÃĻle RDF est ÃĐcrit comme RDF/XML une construction spÃĐciale utilisant un attribut parseType='Literal' est utilisÃĐ pour le reprÃĐsenter.
Dans Jena, ces attributs d'un littÃĐral peuvent Être dÃĐfinis quand le littÃĐral est construit, par exemple dans le tutoriel 11 :
// On crÃĐe la ressource
Resource r = model.createResource();
// ajoute la propriÃĐtÃĐ
r.addProperty(RDFS.label, model.createLiteral("chat", "en"))
.addProperty(RDFS.label, model.createLiteral("chat", "fr"))
.addProperty(RDFS.label, model.createLiteral("<em>chat</em>", true));
// ÃĐcrit le model
model.write(system.out);produit :
<rdf:RDF
xmlns:rdf='http://www.w3.org/1999/02/22-rdf-syntax-ns#'
xmlns:rdfs='http://www.w3.org/2000/01/rdf-schema#'
>
<rdf:Description rdf:nodeID="A0">
<rdfs:label xml:lang='en'>chat</rdfs:label>
<rdfs:label xml:lang='fr'>chat</rdfs:label>
<rdfs:label rdf:parseType='Literal'><em>chat</em></rdfs:label>
</rdf:Description>
</rdf:RDF>Pour que deux littÃĐraux soient considÃĐrÃĐs comme ÃĐgaux, ils doivent Être tous les deux soit des littÃĐraux XML soit de simples littÃĐraux. En outre, soit les deux ne doivent avoir aucune ÃĐtiquette de langue, soit les ÃĐtiquettes de langues sont prÃĐsentes, mais elles doivent Être ÃĐgales. Pour de simples littÃĐraux, les chaÃŪnes de caractÃĻres doivent Être ÃĐgales. Les littÃĐraux XML ont deux notions d'ÃĐgalitÃĐ. La notion simple est que les conditions prÃĐcÃĐdemment mentionnÃĐes soient vraies et les chaÃŪnes de caractÃĻres soient aussi ÃĐgales. L'autre notion est qu'ils peuvent Être ÃĐgaux si la canonisation de leur chaÃŪne de caractÃĻres est ÃĐgale.
Les interfaces de Jena supportent aussi les littÃĐraux typÃĐs. L'ancienne façon (voir ci-dessous) traite les littÃĐraux typÃĐs comme un raccourci pour les chaÃŪnes de caractÃĻres : les valeurs typÃĐes sont converties selon la mÃĐthode habituelle de Java en chaÃŪnes de caractÃĻres et ces chaÃŪnes de caractÃĻres sont stockÃĐes dans le modÃĻle. Par exemple, essayez (en notant que pour de simples littÃĐraux, nous pouvons omettre l'appel à model.createLiteral()) :
// On crÃĐe la ressource
Resource r = model.createResource();
// ajoute la propriÃĐtÃĐ
r.addProperty(RDFS.label, "11")
.addProperty(RDFS.label, 11);
// affiche le model
model.write(system.out, "N-TRIPLE");La sortie produite est :
_:A... <http://www.w3.org/2000/01/rdf-schema#label> "11" .Ãtant donnÃĐ que les deux littÃĐraux sont rÃĐellement juste la chaÃŪne de caractÃĻres ÂŦÂ 11Â Âŧ, alors une seule dÃĐclaration est ajoutÃĐe.
Le groupe de travail RDFCore a dÃĐfini des mÃĐcanismes pour soutenir les types de donnÃĐes en RDF. Jena supporte ces utilisations des mÃĐcanismes de littÃĐral typÃĐ ; ils ne sont pas abordÃĐs dans ce tutoriel.
XII. Glossaire▲
NÅud anonyme : reprÃĐsente une ressource, mais n'indique pas une URI pour la ressource. Les nÅuds anonymes agissent comme des variables existentiellement qualifiÃĐes dans la logique du premier ordre.
Dublin Core : un standard pour les mÃĐtadonnÃĐes sur les ressources Web. De plus amples informations peuvent Être trouvÃĐes sur le site Web de Dublin Core.
LittÃĐral : une chaÃŪne de caractÃĻres qui peut Être la valeur d'une propriÃĐtÃĐ.
Objet : la partie d'un triplet qui est la valeur de la dÃĐclaration.
PrÃĐdicat : la partie de la propriÃĐtÃĐ dans un triplet.
PropriÃĐtÃĐÂ : une propriÃĐtÃĐ est un attribut d'une ressource. Par exemple, DC.Title est une propriÃĐtÃĐ, comme l'est RDF.type.
Ressource : certaines entitÃĐs. Elle pourrait Être une ressource Web comme une page Web, ou une chose physique concrÃĻte comme un arbre ou une voiture. Elle pourrait Être une idÃĐe abstraite comme les ÃĐchecs ou le football. Les ressources sont nommÃĐes par une URI.
DÃĐclaration : un arc dans un modÃĻle RDF, normalement interprÃĐtÃĐ comme un fait.
Sujet : la ressource qui est la source d'un arc dans un modÃĻle RDF.
Triplet : une structure contenant un sujet, un prÃĐdicat et un objet. Un autre terme pour une dÃĐclaration.
XIII. L'article original▲
Cet article est la traduction de An Introduction to RDF and the Jena RDF API.
XIV. Remerciements▲
Merci à Claude Leloup, jacques_jean, Mathieu Robin et _Max_ pour leur relecture orthographique.